Data-Lab
In addition to traditional business resources, ddata is increasingly becoming one of, if not the most, business-critical basis for optimising processes, making decisions and improving or developing new business models. Companies increasingly rely on methods of business analytics, data science, process analytics and artificial intelligence. Some of the members of our department are therefore involved in the application of machine learning and deep learning, XAI and transferlearning. Our focus is on the context of operational information systems, i.e. the application of data-driven approaches within or on the basis of operational information systems. Based on the ERP-Lab set up by the chair and driven by the DeepScan and PipeAI research projects, our chair has built up a testbed that can be used for research and teaching in the area of data engineering and data pipelines.
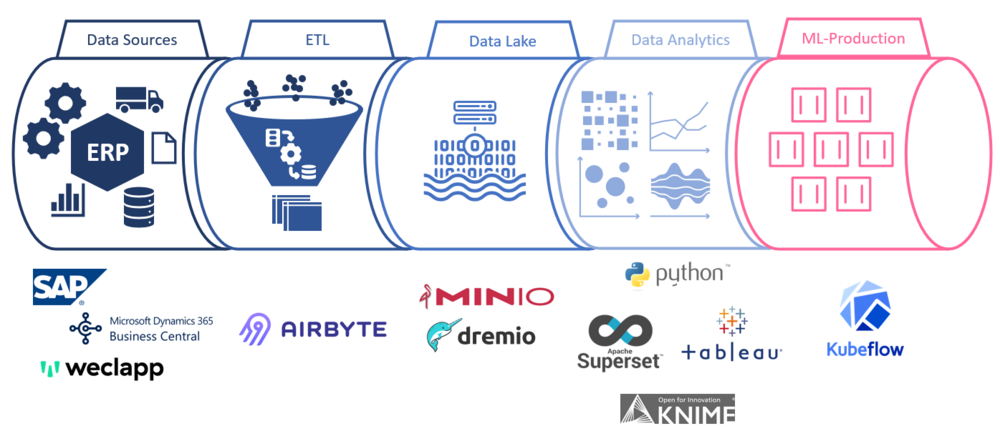
The testbed was set up as an ML pipeline that can be used to develop data-driven processes, business analytics and machine and deep learning processes and to test the transfer of solutions into productive operation. In total, the ML pipeline consists of two servers that host various software components and a Kubernetes development and test cluster. The data lab thus provides an infrastructure to simplify the development process from exploratory data analyses, through the development of an MVP, to testing under real conditions.
Airbyte's software solution, which is based on (reverse) ETL procedures, can be used to connect interfaces and databases of business application systems in the ERP lab and extract data from them. A local blob storage (min.io) or a relational database serves as data storage for the extracted data. Based on a data semantics layer (dremio), the data can be read for evaluation based on relational schemas and analysed, for example, in the Apache Superset Analytics platform provided or also local analytics clients such as Tableau, Power BI or KNIME. The Kubernetes cluster also offers the possibility to host developed Machine Learning and Deep Learning models container-based.
Our ML pipeline is currently not actively used in any courses at the department; it is only used in exercises, for individual demonstrations and various research projects.
However, interested students have the opportunity to gain access to the used solutions, e.g. for seminar papers or theses.